Unicode
Create by fall on 16 May 2024
Recently revised in 16 May 2024
grapheme:用户所认为的一个字符
extended grapheme cluster:多个字节拼合成一个字符(
Unicode 知识
这篇文章讲的很好(每个程序员必须知道的关于 unicode 的知识):https://tonsky.me/blog/unicode/
UTF-32
最简单的,固定占据 32 位,因为最高定义的代码点是 U+10FFFF,所以任何代码点都保证适合。
UTF-32 在操作二进制码点(code point)的时候很有用,在几乎全部的情况下,你不需要操作码点。
grapheme 表示用户认为他是单个字符,而这个字符在 UTF-8 中的长度是不固定的
- ☹️ 是
U+2639+ `U+FE0F - 👨🏭 is
U+1F468+U+200D+U+1F3ED(女人,加医院) - 🚵🏻♀️:
U+1F6B5+U+1F3FB+U+200D+U+2640+U+FE0F
而且没有长度限制,这导致,在 UTF-32 中 👨🏭 仍会占据 4 bytes
UTF-32 替代 UTF-8 并不会让单个字符处理更容易,也容易导致字符串分离,所以应该采取的方式是使用 grapheme 簇表示一个字符。
UTF-16
不如 UTF-32 那么直接
UTF-8
UTF-8 长度可变,可能为 1 - 4 bytes
| Code point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+0000..007F | 0xxxxxxx | |||
U+0080..07FF | 110xxxxx | 10xxxxxx | ||
U+0800..FFFF | 1110xxxx | 10xxxxxx | 10xxxxxx | |
U+10000..10FFFF | 11110xxx | 10xxxxxx | 10xxxxxx | 10xxxxxx |
一般来讲,英文占据 1 byte, 欧洲的语言需要 2 byte,Chinese, Japanese, Korean, other Asian languages, and Emoji need 3 or 4.
并且 UTF-8 兼容 ASCII 码,0 - 127,占据 1 byte,任何合法的 ASCII 码都是合格的 UTF-8 码,可以直接读取
UTF-8 第一个 byte 前缀和后面 2-4 位的不同,因此能检测出问题,并拥有以下规则
- 使用继续读取前缀的字段,你不能决定这些字段的长度
- 你不能随机到一些字段的中间,然后进行读取
- 不能通过切割字节来获取子字符串,你可能会切断字符的一部分
如果切割错误字符串,将会出现 � 字符
U+FFFD,替换字符,Unicode 出现错误时,会使用该字符进行代替。如果你将一个多字节的字符串切成两半,会出现该字符,表示解析 UTF-8 错误。
FAQ
🤦🏼♂️长度是多少
Python 3:5
JavaScript / Java / C#:7
实际上 🤦🏼♂️ 有五个码点组成(U+1F926 U+1F3FB U+200D U+2642 U+FE0F)在不同语言中实现方式不同
- 本质有几个字节与计算机有关,如何复制 string,将他们在网络上传输,如何存储在 disk 中。这时,只需考虑如何复制整个字符串,而不用考虑他的内容
- 如何包装,所使用的 API 会计算当前字节,同样的文字,
swift会给予 1 个字节
"ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length有多长?
如何检测扩展字符簇
扩展字符簇(extended grapheme clusters)
大多数语言都不支持单个扩展字符簇的检测,但几乎都采用相同的工具 ICU
字符(grapheme)会随着时间添加更多的字符,每年都会修正它的版本
同样的字符不相等?
"Å" !== "Å" !== "Å"
"Å" === "Å" // false
"Å" === "Å" // false
"Å" === "Å" // false
有多种字符添加方式
Å通过A+ 一个组合字符- 还有一个预先组合的字码,
U+00C5
它们看起来一样,预期的结果也应该相同,唯一的不同是二进制,这是我们需要标准的理由,有四个标准
NFD 试图将所有内容,拆分为尽可能小的部分,然后将这些部分排序,如果不止有一个的话
NFC 试图将所有的内容都组合起来,如果存在的话
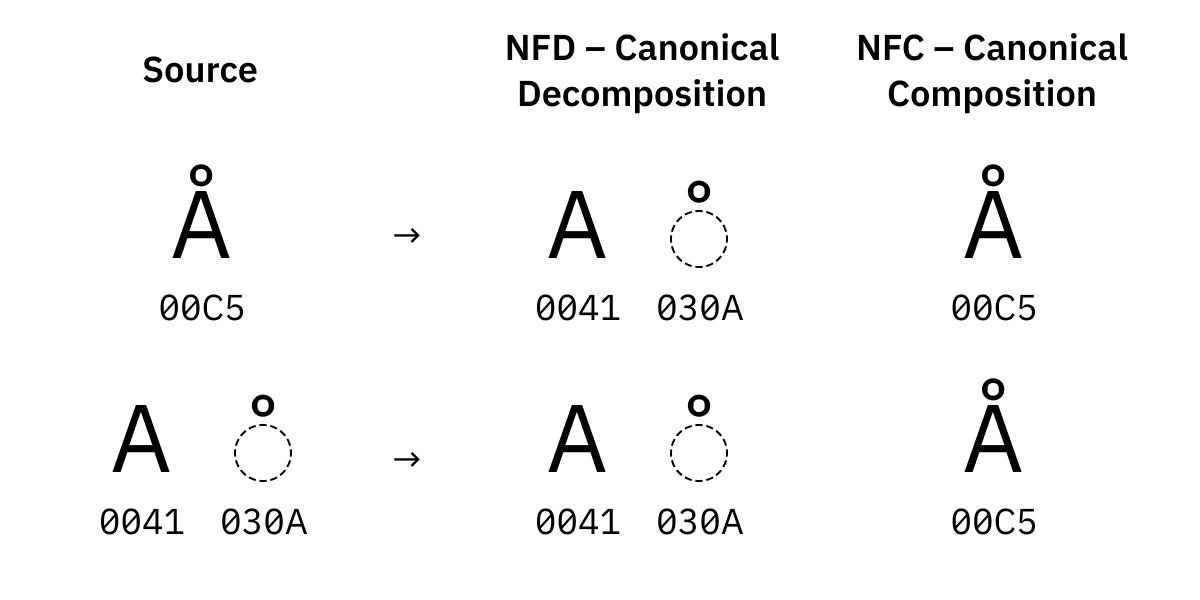
对于一些字符来说,有多个版本的相同字符(看起来一样
U+00C5Latin Capital Letter A with Ring Above(拉丁字母,有一个圆在侧)U+212B埃及字符
对于 NFD,NFC 来讲,都是很标准的实现方式,对于下面的内容,就更偏向于兼容
- NFKD 试图拆解一切,并用默认的替换视觉变体
- NFKC 试图合并一切,同时用默认的替换视觉变体

Unicode 和本地化有关
俄语中,Nikolay Unicode 是: U+041D 0438 043A 043E 043B 0430 0439。写作:
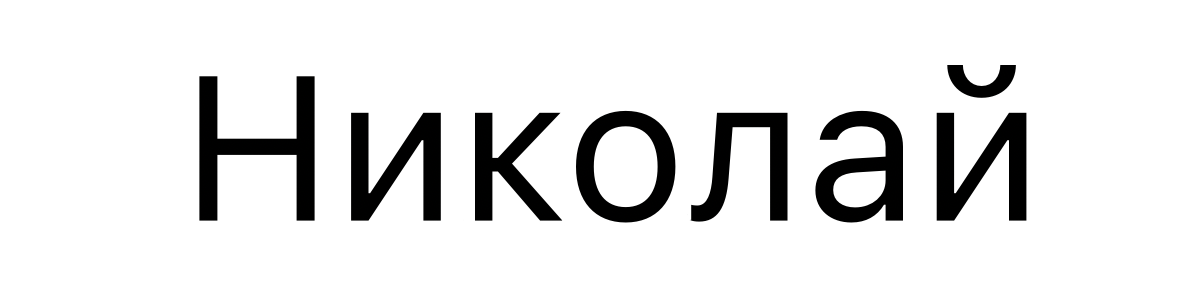
保加利亚语 Nikolay Unicode 也是: U+041D 0438 043A 043E 043B 0430 0439。但写作:
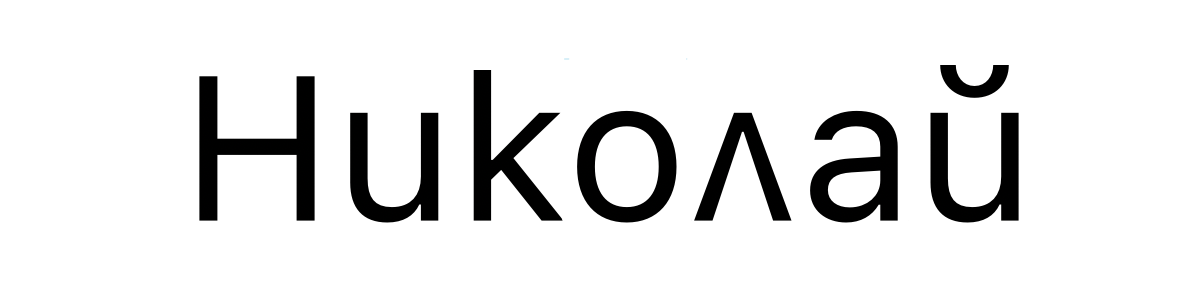
那什么时候渲染保加利亚语,什么时候渲染俄语呢?不知道,因为 Unicode 并不是一个完美的系统,有它的不足,就像是把相同的码位分配给不同的字形。亚洲更是重灾区,许多中文,日文,韩文写的都不同但拥有相同的码位

这也违反了 Unicode 的初衷,不需要任何转换就可以指定任何语言的任何字符
no escape sequence or control code is required to specify any character in any language.
为什么 toLowerCase 有 local 参数
土耳其有两种 i
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"
// 如果你不知道你输入的语言,你不能确定转换的方式是否正确
英语环境就不用担心 unicode 吗

- quotation marks
“”‘’, - apostrophe
’(省字符,is not -> isn’t) - dashes
–—, - different variations of spaces (figure, hair, non-breaking),
- bullets
•■☞, - currency symbols other than the
$(kind of tells you who invented computers, doesn’t it?):€¢£, - mathematical signs—plus
+and equals=are part of ASCII, but minus−and multiply×are not ¯_(ツ)_/¯, - various other signs
©™¶†§.
甚至没有 Unicod 就不能拼出 café, piñata, or naïve
什么是代理对
Unicode 的第一个版本应该是固定宽度的。准确地说,是 16 位固定宽度,它们认为 65,536 个字符足以涵盖所有人类语言。
实际上,从 U+D800 到 U+DFFF 的整个范围都被分配为「仅用于代理对」。从那里开始的码位甚至在任何其他编码中都不被认为是有效的。
许多语言都因为 utf-16 定长,涵盖所有语言的编码,而采用。Microsoft Windows、Objective-C、Java、JavaScript、.NET、Python 2、QT、短信,还有 CD-ROM!
在今天的实际情况下,UTF-16 的可用性与 UTF-8 大致相同。它的长度也是可变的;计算 UTF-16 单元与计算字节或码位一样没有用,字位簇仍然很痛苦,等等。唯一的区别是内存需求。
UTF-16 的唯一缺点是其他所有东西都是 UTF-8,因此每次从网络或磁盘读取字符串时都要转换一下。
总结
- Unicode 已经赢了。
- UTF-8 是传输和储存数据时使用最广泛的编码。
- UTF-16 仍然有时被用作内存表示。
- 字符串的两个最重要的视图是字节(分配内存/复制/编码/解码)和扩展字位簇(所有语义操作)。
- 以码位为单位来迭代字符串是错误的。它们不是书写的基本单位。一个字位可能由多个码位组成。
- 要检测字位的边界,你需要 Unicode 表格。
- 对于所有 Unicode 相关的东西,甚至是像
strlen、indexOf和substring这样的无聊的东西,都要使用 Unicode 库。 - Unicode 每年更新一次,规则有时会改变。
- Unicode 字符串在比较之前需要进行归一化。
- Unicode 在某些操作和渲染中依赖于区域设置。
- 即使是纯英文文本,这些都很重要。
总的来说,是的,Unicode 不完美,但
- 有一个能覆盖所有可能语言的编码、
- 全世界都同意使用它、
- 我们可以完全忘记编码和转换之类的东西
参考文章
| 作者 | 链接 |
|---|---|
| Niki | The Absolute Minimum Every Software Developer Must Know About Unicode in 2023 |